Aprenda a utilizar el Machine Learning o aprendizaje automatico para una investigación de la competencia SEO más precisa, estadísticamente relevante y escalable (con herramientas, código y más).
Con el creciente apetito de los profesionales del SEO por aprender Python, nunca ha habido un momento mejor o más emocionante para aprovechar las capacidades del aprendizaje automático (ML) y aplicarlas al SEO.
Esto es especialmente cierto en su investigación de la competencia.
En esta columna, usted aprenderá cómo el aprendizaje automático ayuda a abordar los desafíos comunes en la investigación de la competencia de SEO, cómo configurar y entrenar su modelo de ML, cómo automatizar su análisis, y más.
¡Vamos a hacerlo!
Por qué usar el Machine Learning en la investigación de la competencia SEO
La mayoría, si no todos los profesionales de SEO que trabajan en mercados competitivos, analizarán las SERPs y sus competidores comerciales para averiguar qué es lo que su sitio está haciendo para lograr un rango más alto.
En 2003, utilizábamos hojas de cálculo para recopilar datos de las SERP, con columnas que representaban diferentes aspectos de la competencia, como el número de enlaces a la página principal, el número de páginas, etc.
En retrospectiva, la idea era correcta pero la ejecución era desesperante debido a las limitaciones de Excel para realizar un análisis estadísticamente sólido en el poco tiempo que se requería.
Y por si los límites de las hojas de cálculo no fueran suficientes, el panorama ha avanzado bastante desde entonces, ya que ahora tenemos
- SERPs móviles.
- Medios sociales.
- Una experiencia de búsqueda en Google mucho más sofisticada.
- Velocidad de la página.
- Búsqueda personalizada.
- Schema.
- Frameworks de Javascript y otras nuevas tecnologías web.
Lo anterior no es en absoluto una lista exhaustiva de tendencias, sino que sirve para ilustrar la gama cada vez mayor de factores que pueden explicar la ventaja de sus competidores mejor clasificados en Google.
El aprendizaje automático en el contexto del SEO
Afortunadamente, con herramientas como Python/R, ya no estamos sujetos a los límites de las hojas de cálculo. Python/R puede manejar de millones a miles de millones de filas de datos.
En todo caso, el límite es la calidad de los datos que puedes introducir en tu modelo de ML y las preguntas inteligentes que haces a tus datos.
Como profesional del SEO, puede marcar la diferencia decisiva para su campaña de SEO cortando el ruido y utilizando el aprendizaje automático sobre los datos de la competencia para descubrir:
- Qué factores de clasificación pueden explicar mejor las diferencias de clasificación entre sitios.
- Cuál es el punto de referencia ganador.
- Cuánto vale una unidad de cambio en el factor en términos de clasificación.
Como cualquier empresa de ciencia (de datos), hay que responder a una serie de preguntas antes de empezar a codificar.
¿Qué tipo de problema ML es el análisis de la competencia?
El ML resuelve una serie de problemas, ya sea para categorizar cosas (clasificación) o para predecir un número continuo (regresión).
En nuestro caso particular, ya que la calidad del SEO de un competidor se denota por su rango en Google, y ese rango es un número continuo, entonces el problema de ML es uno de regresión.
Métrica de resultados
Dado que sabemos que el problema de ML es de regresión, la métrica de resultado es el rango. Esto tiene sentido por varias razones:
- El rango no se verá afectado por la estacionalidad; la clasificación de una marca de helados en las búsquedas de [helados] no se depreciará porque sea invierno, a diferencia de la métrica «usuarios».
- El ranking de la competencia es un dato de terceros y está disponible mediante herramientas comerciales de SEO, a diferencia del tráfico de usuarios y las conversiones.
¿Cuáles son las características?
Conociendo la métrica del resultado, ahora debemos determinar las variables independientes o entradas del modelo también conocidas como características. Los tipos de datos para la característica variarán, por ejemplo:
- La primera pintura medida en segundos sería un dato numérico.
- El sentimiento con las categorías positivo, neutro y negativo sería un factor.
Naturalmente, se desea cubrir tantas características significativas como sea posible, incluyendo las técnicas, de contenido/UX, y fuera del sitio para la investigación más completa de la competencia.
La matemática
Dado que las clasificaciones son numéricas, y que queremos explicar la diferencia de rango, entonces en términos matemáticos
rank ~ w_1*feature_1 + w_2*feature_2 + … + w_n*feature_n
~ (conocida como «tilde») significa «explicado por»
n es la enésima característica
w es la ponderación de la característica
Cómo utilizar el machine learning para descubrir los secretos de la competencia
Con las respuestas a estas preguntas en la mano, estamos listos para ver qué secretos puede revelar el aprendizaje automático sobre su competencia.
En este punto, asumiremos que sus datos (conocidos en este ejemplo como «serps_data») han sido unidos, transformados, limpiados, y ahora están listos para ser modelados.
Como mínimo, estos datos contendrán los datos de rango y características de Google que quieras probar.
Por ejemplo, sus columnas podrían incluir
- Google_rank.
- Page_speed.
- Sentiment.
- Flesch_kincaid_reading_ease.
- Amp_version_available.
- Site_depth.
- Internal_page_rank.
- Referring_comains count.
- avg_domain_authority_backlinks.
- title_keyword_string_distance.
Entrenamiento de su modelo Machine Learning (ML)
Para entrenar su modelo, utilizamos XGBoost porque tiende a ofrecer mejores resultados que otros modelos ML.
Otras alternativas que puede probar en paralelo son LightGBM (especialmente para conjuntos de datos mucho más grandes), RandomForest y Adaboost.
Pruebe a utilizar el siguiente código de Python para XGBoost para su conjunto de datos de SERPs:
importar las bibliotecas
import xgboost as xgb
import pandas as pd
serps_data = pd.read_csv('serps_data.csv')Establecer las variables del modelo
Tus datos de SERPs con todo menos la columna google_rank
serp_features = serps_data.drop(columns = ['Google_rank'])
tus datos de las SERPs con sólo la columna google_rank
rank_actual = serps_data.Google_rank
Iniciar el modelo
serps_model = xgb.XGBRegressor(objective='reg:linear', random_state=1231)
Ajustar el modelo
serps_model.fit(serp_features, rank_actual)
Generar las predicciones del modelo
rank_pred = serps_model.predict(serp_features)
Evaluar la precisión del modelo
mse = mean_squared_error(rank_actual, rank_pred)
Tenga en cuenta que lo anterior es muy básico. En un escenario de cliente real, querrías probar varios algoritmos de modelos en una muestra de datos de entrenamiento (alrededor del 80% de los datos), evaluar (usando el 20% de datos restante), y seleccionar el mejor modelo.
Entonces, ¿Qué secretos puede contarnos este modelo de aprendizaje automático?
Los Factores mas importantes de la clasificación
El gráfico muestra las características o factores de clasificación de las SERP más influyentes en orden descendente de importancia.
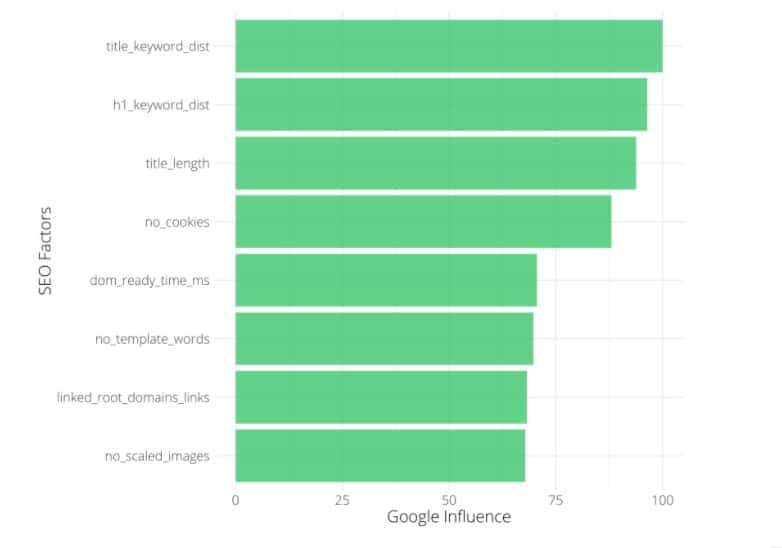
Características de las SERP o factores de clasificación más influyentes por orden de importancia.
En este caso concreto, el factor más importante fue «title_keyword_dist», que mide la distancia entre la etiqueta del título y la palabra clave objetivo. Piensa en esto como la relevancia de la etiqueta del título para la palabra clave.
No es una sorpresa para el profesional de SEO, sin embargo, el valor aquí es proporcionar evidencia empírica a la audiencia de negocios no experta que no entiende la necesidad de optimizar las etiquetas de título.
Otros factores a destacar en este sector son
- no_cookies: El número de cookies.
- dom_ready_time_ms: Una medida de la velocidad de la página.
- no_template_words: Cuenta el número de palabras fuera de la sección de contenido del cuerpo principal.
- link_root_domains_links: Cuenta los enlaces a dominios raíz.
- no_scaled_images: Recuento de imágenes escaladas que necesitan ser escaladas por el navegador para ser renderizadas.
Cada mercado o industria es diferente, por lo que lo anterior no es un resultado general para todo el SEO.
Cuánto influye un factor de clasificación en las SERP’s
En otro caso del mercado, también podemos ver cuánto rango se entregará en la clasificación.
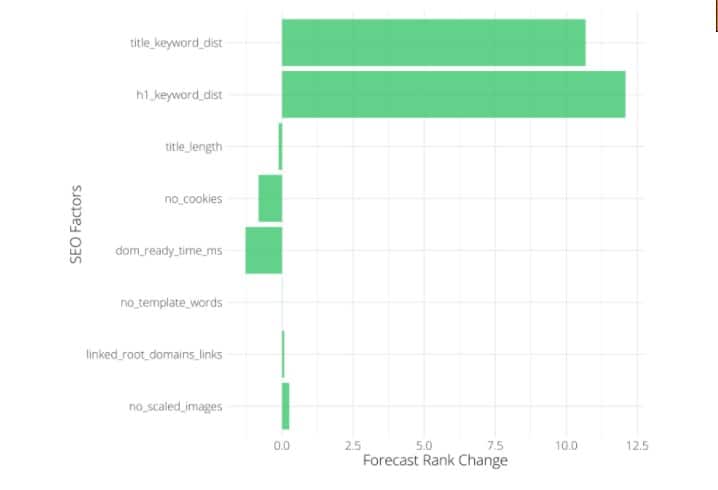
Previsión de cambio de rango.
En el gráfico anterior, tenemos una lista de factores y el cambio de rango para cada cambio de unidad positiva en ese factor.
Por ejemplo, por cada unidad de aumento de la longitud de la meta descripción en 1 carácter, hay una disminución correspondiente en el rango de Google de 0,1.
Fuera de contexto, esto parece ridículo. Sin embargo, dado que la mayoría de las meta descripciones están pobladas, significaría que un cambio de unidad de la longitud media de la meta descripción conduciría a una disminución de la clasificación en la búsqueda de Google.
El punto de referencia ganador de un factor de clasificación
A continuación se muestra un gráfico que representa la longitud media de la etiqueta del título para un sector diferente al anterior, que también incluye una línea de mejor ajuste:
Gráfico de la longitud media de la etiqueta del título.
A pesar de la recomendación de las mejores prácticas de SEO de utilizar hasta 70 caracteres para la longitud de la etiqueta del título, los datos trazados arriba muestran que la longitud óptima real en esta industria es de 60 caracteres.
Gracias al aprendizaje automático, no sólo somos capaces de sacar a la luz los factores más importantes, sino que al hacer una inmersión profunda también podemos ver el punto de referencia ganador.
Automatizar el análisis de la competencia SEO con el aprendizaje automático
La aplicación anterior del aprendizaje automático es genial para obtener algunas ideas para dividir la prueba AB y mejorar el programa de SEO con solicitudes de cambio basadas en pruebas.
También es importante reconocer que este análisis se hace aún más poderoso cuando es continuo.
¿Por qué?
Porque el análisis ML es sólo una instantánea de las SERPs para un único punto en el tiempo.
Tener un flujo continuo de recopilación y análisis de datos significa que se obtiene una imagen más real de lo que está sucediendo realmente con las SERPs para su industria.
Aquí es donde los sistemas de almacenes de datos y tableros de control creados específicamente para el SEO resultan útiles, y estos productos están disponibles hoy en día.
Lo que hacen estos sistemas es
- Ingerir los datos de sus herramientas SEO favoritas diariamente.
- Combinar los datos.
- Utilizar el lenguaje de programación (ML) para obtener información como la mencionada anteriormente en una interfaz de su elección, como Google Data Studio.
Para construir su propio sistema automatizado, usted debe desplegar una infraestructura de nube como Amazon Web Services (AWS) o Google Cloud Platform (GCP) lo que se llama ETL, es decir, extraer, transformar y cargar.
Para explicar:
- Extraer – Llamada diaria a las APIs de su herramienta SEO.
- Transformar – La limpieza y el análisis de sus datos utilizando ML como se ha descrito anteriormente.
- Cargar – Depositar el resultado final en su almacén de datos.
- De este modo, la recopilación, el análisis y la visualización de los datos se automatizan en un solo lugar.
¿TL;DR?
La investigación y el análisis de la competencia en SEO es difícil porque hay muchos factores de clasificación para controlar.
Las herramientas de hoja de cálculo no están a la altura, debido a la cantidad de datos que se manejan (por no hablar de las capacidades estadísticas que ofrecen los lenguajes de ciencia de datos como Python).
Cuando se realiza un análisis de la competencia SEO utilizando el aprendizaje automático, es importante entender que se trata de un problema de regresión, la variable objetivo es el rango de Google, y que las hipótesis son los factores de clasificación.
El uso de ML en sus competidores puede decirle cuáles son los impulsores clave, identificar los puntos de referencia ganadores entre ellos, e informar de la cantidad de elevación en el rango que sus optimizaciones pueden ofrecer potencialmente.
El análisis es sólo una instantánea, así que para estar al tanto de los competidores, automatice este proceso utilizando Extract, Transform, Load (ETL).